
"확률적 계산이 필요한 게임에서 인간은 인공지능을 이길 수 없다"
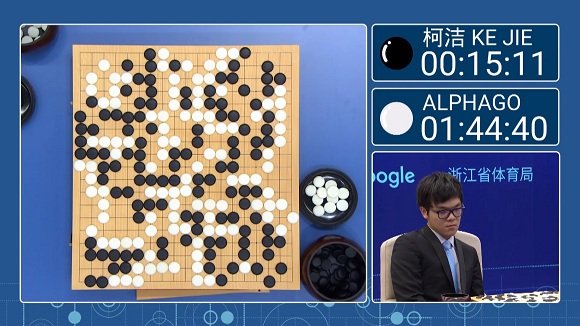
세계랭킹 1위의 바둑기사 커제 9단도 구글의 딥마인드가 개발한 인공지능(AI) 알파고에 속절없이 무너졌다. 알파고는 289수만에 한 집 반 승리를 거뒀다.
모두가 예상했던 결과였다. 사람들은 커제 9단이 이길 수 있을까 보다는 알파고가 얼마나 강해졌는가에 더 초점을 맞췄다. 이번 대국에 나선 알파고는 1년 전에 비해 향상된 성능을 가진 2.0 버전으로 알려졌다.
입력된 기보에 의한 학습이 아닌 강화학습(reinforcement learning)을 통해 알파고는 더욱 강력한 모습을 선보였다. 더 이상 기보 등의 데이터 입력을 배제하고 알파고와 알파고의 대결을 통해 성능을 끌어올렸을 것으로 전문가들은 추정하고 있다.
지난해 이세돌 9단과 알파고의 대국을 앞두고 유일하게 알파고의 완승을 점쳤던 이는 김진호 서울과학종합대학원 빅데이터 MBA학과 교수다. 그는 이번 커제 9단과 알파고의 대결을 "호날두와 고교 축구선수의 대결"로까지 표현하며 계산의 영역에서 인간이 기계를 넘어설 수 없다고 주장했다.
그는 직관(insight)이 필요하다고 여겨진 게임에서 직관이 없는 알파고가 이길 수 밖에 없었던 이유에 대해, 기본적으로 계산이 필요한 확률게임에서 인간이 인공지능을 이길 수 없다고 단언했다.
예를들어 돌을 놓을 수 있는 곳이 250곳이 있다면, 인간은 경험과 학습한 내용을 바탕으로 모양과 형세를 판단해 10곳 이내의 착점으로 압축하고 수 계산을 한다. 가장 유리한 곳의 범위를 좁힐 때 인간이 사용하는 것이 직관이다.
반면 알파고는 250곳 모두에 대해 경우의 수를 따져본 후 제일 이득이 큰 곳을 찾는다. 직관이 개입할 여지는 없다. 지난해 이세돌 9단과의 제1국에서 많은 프로 기사들이 경기가 진행되는 초반 및 중반까지도 이세돌 9단의 우세를 점쳤다가 결과적으로 패하는 장면을 보고 충격을 받았다. "지금까지의 정석을 다시 생각해 봐야 할 것"이라는 얘기까지 나왔다.
◇ 놀라운 연산을 가능케 하는 알파고의 두뇌 'TPU(Tensor Processing Unit)'
그렇다면 불가능에 가깝다고 여겨진, 혹은 아주 오랜 시간이 걸릴 것으로 예측된 바둑이라는 게임 안에서의 연산을 알파고는 어떻게 진행할까.
알파고 v.18은 일반적인 컴퓨팅에 쓰이는 CPU(중앙처리장치) 1202개, 그래픽칩에 쓰이는 GPU 176개, 64GB D램 모듈 92만3136개가 병렬 연결된 시스템을 사용한 것으로 알려졌다.
이런 시스템은 대용량 서버와 슈퍼컴퓨터가 작동할 데이터센터를 필요로 한다. 데이터센터에서 발생하는 열을 식힐 냉각장치도 필수 요소다. 이를 위해 엄청난 양의 전력이 소모된다.
그리고 알파고는 바둑뿐만 아니라 다양한 빅데이터 처리에도 사용되며, 매일 축적되는 데이터의 양은 점차 방대해 지고 있다.

이를 해결하기 위해 구글은 연산능력이 더 뛰어난 프로세서를 개발했다. 데이터센터의 면적을 늘리는 대신 적은 숫자의 프로세서로 같은 양의 연산을 처리할 수 있는 방법을 선택한 셈이다.
이렇게 탄생한 프로세서가 텐서 프로세싱 유닛 TPU(Tensor Processing Unit)다. 머신러닝에 특화된 칩셋으로, 구글이 공개한 자료에 의하면 기존에 사용하던 GPU/CPU 조합보다 15~30배 가량 높은 성능을 갖췄다. 머신러닝 구동시 와트당 성능도 향상시켜 전력 소모 걱정을 덜었고, 연산 운영당 트랜지스터 필요성도 낮췄다.
딥러닝, 머신러닝 등을 위한 연산은 일반적으로 사용되는 CPU보다 병렬연산에 최적화된 GPU가 유리하다. GPU는 많은 데이터를 한 번에 처리할 수 있도록 코어에서 복잡한 연산에 필요한 부분을 제외하고 숫자를 늘리는 방식을 택했다. GPU 부문 업계 1위는 엔비디아로 인공지능 시대의 도래와 함께 더욱 성장해 나가고 있다. 최근 엔비디아가 발표한 '볼타' 아키텍처 기반의 V100칩에는 무려 5120개의 쿠다 프로세서가 탑재됐다.
엔비디아는 CPU에 걸리는 과부하를 나눠 계산하기 위해 GPGPU를 개발했다. 기존의 GPU를 CPU가 맡았던 연산에 활용하기 위해서다. 해당 기술은 날로 발전해 현재 자율주행차 등의 프로세서로 GPGPU가 선택되는 추세다.
엔비디아의 V100은 기존까지 가장 빨랐던 파스칼 아키텍처에 비해 5배, 2년 전 출시된 멕스웰에 비해 15배 향상된 120테라플롭스의 속도를 구현했다.
구글이 알파고 2.0에 사용한 TPU는 이보다 빠른 180테라플롭스의 속도를 내는 것으로 알려졌다. 이번 커제 9단과의 대국에서도 구글은 1대의 TPU가 사용됐다고 밝혔다.
백성요 기자 sypaek@greened.kr
